Python网络爬虫
最近需要画网页,所以急需一批设计稿来提供灵感。所以第一个想到去 www.dribbble.com 找素材。无奈一个是国内连过去网速比较慢,而且一点一点翻效率也比较低,所以就萌生了做一个网络爬虫批量下载图片的想法。
之前也想过要用布隆过滤器做一个网络爬虫,后来搁置了。以后填坑。
我写的时候参见了教程Here。PS:BeautifulSoup 真心好用。强大的第三方库加上Python本身优雅的语法设计,50行的python抵200行的Java我没开玩笑。
先配虚拟环境virtualenv,是一个与外界独立的开发环境。你可以在里面安装各种包而不会影响到外界,外界的配置变化也不会影响到你(不会出现代码慢慢就腐烂了,多年以后编译都通不过的情况)。还有一个好处就是你可以采用一些实现特定功能的特殊配置而不与外界冲突,比如我现在要写的爬虫也算吧,以后写爬虫都在这里写了,嗯嗯。
这里是配置环境,过不了的自行Google
$ mkdir pycon-scraper
$ virtualenv venv
$ venv\Scripts\activate
(venv) $ pip install requests beautifulsoup4在写一个爬虫脚本时,第一件事情就是手动观察要抓取的页面来确定数据如何定位。因为我要找素材,所以我搜索了关键字 “order page” -> 点菜网页,然后我准备把我搜到的图片全都抓下来。
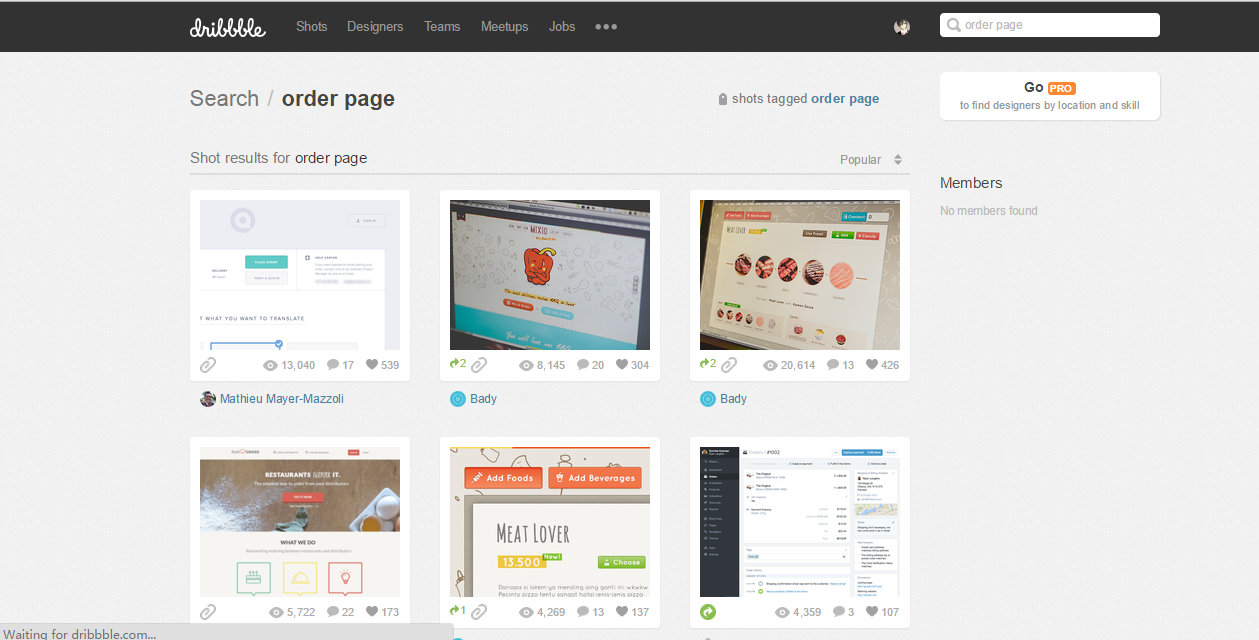
这是我要批量下载图片的地方。可以看见下面的列表,我要在HTML标记中找出一定的规律,然后定位我要找的URL。
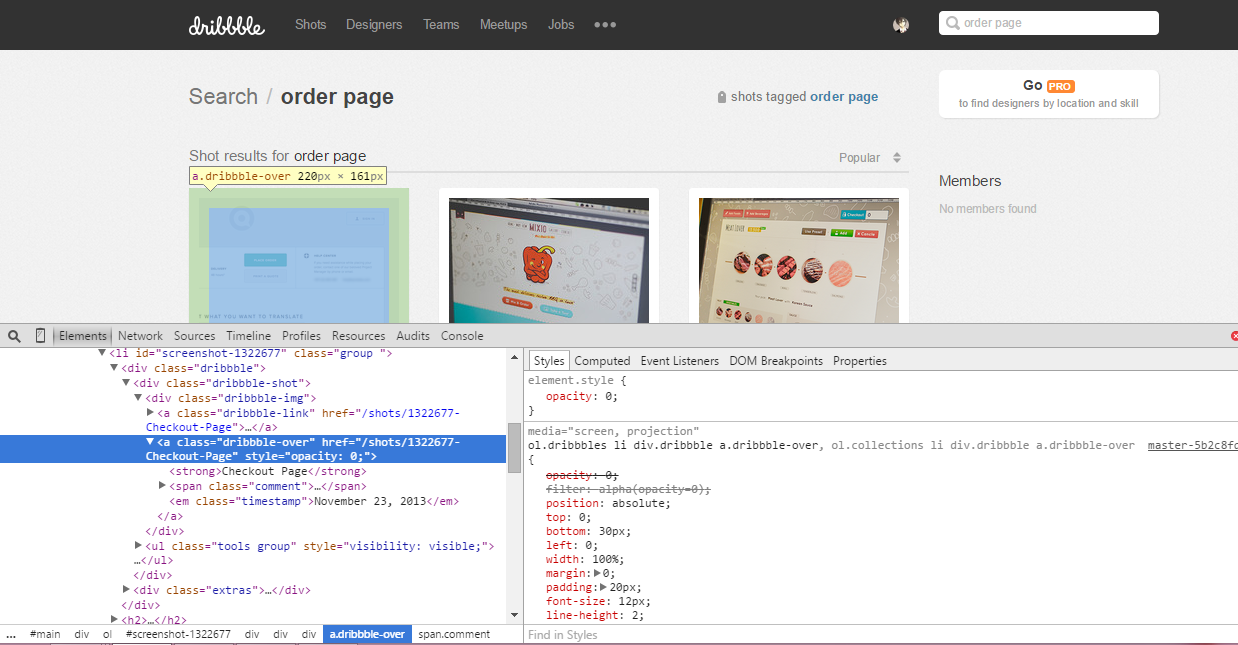
然后就是用beautifulsoup来获取这些URL地址了。URL支持CSS语法查找,用类名和id来搜索。我们注意到在标签<a><a/>外面套了一层class="dribbble-img"的div,所以我们就用这个特征进行抓取。
import requests
import bs4
import urllib.request
root_url = 'https://dribbble.com'
search_url = '/search?q=order+page'
index_url = root_url+ search_url
def get_page_urls(page_url):
response = requests.get(page_url)
soup = bs4.BeautifulSoup(response.text)
return [a.attrs.get('href') for a in soup.select('div.dribbble-img a')]
print(get_page_urls(index_url))来,验证一下,还有点小小的成就感呢。
现在我们把这个页面上12.。。不,是24个链接抓下来了,,,,怎么多了12个?因为图片下面还有个链接。。。当时我写代码的时候没看见,不过后来可以用python的切片语法过滤掉(有点像Matlab里面的矩阵运算)。
但是光有这个链接还不够,我们还要到图片的源网页去抓大图。(小图看不清啊,所以我没有直接抓图片列表里的 <img XXX 的字段。
我们像机智的警犬开始寻找猎物。点击列表中的图片,看看这里有什么。
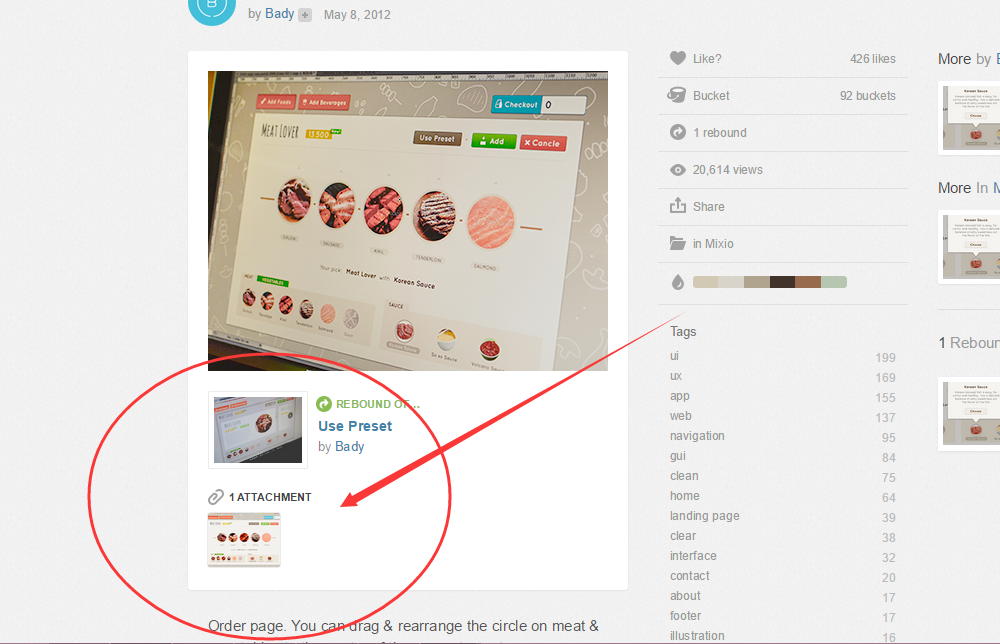
一开始我直接把这里的图片爬下来了,图片还是太小,有些细节还是看不清楚,不能直接当设计稿。
咦,这是什么?
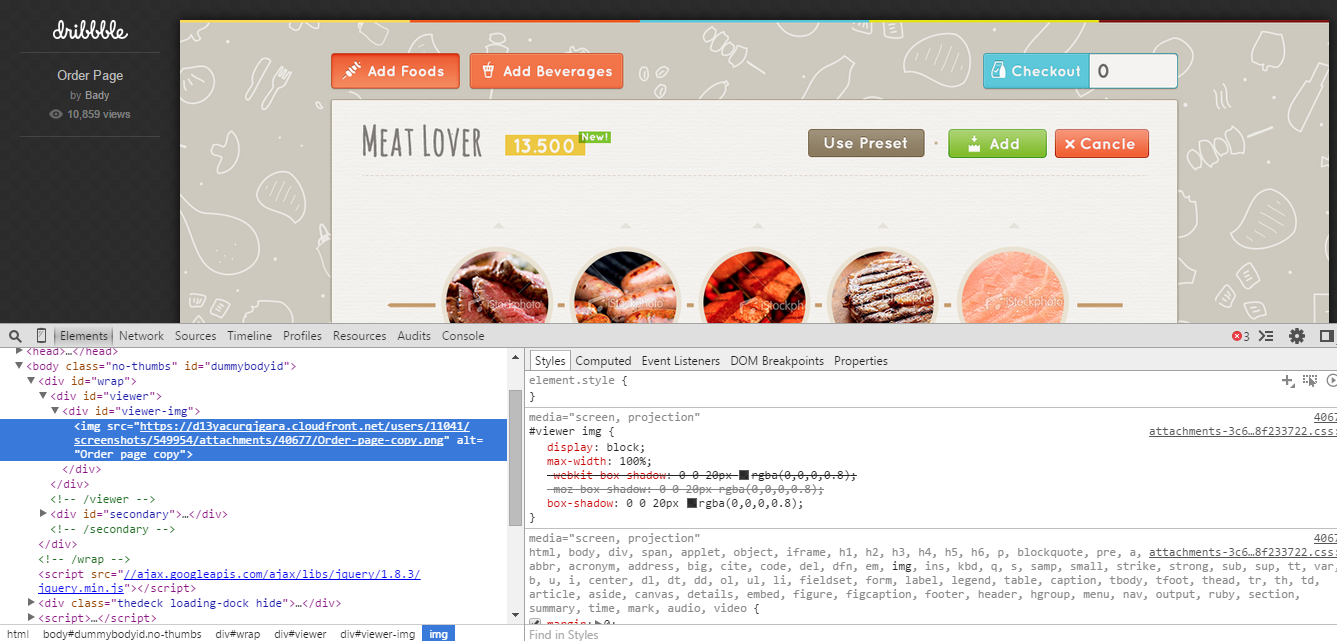
这才是我们想要的。
- 首先我们要获得搜索结果中的列表URL–>
get_page_urls(page_url) - 然后进入专属页面,如果有attachment的返回大图的地址,没有则返回专属页面中小图的地址。–>
get_img_url(half_url) - 根据斜杠
/分割字符串,用作保存图片的文件名和后缀名,下载图片。
Wait
我们好像只爬了当前一个搜索页。What’s Next?
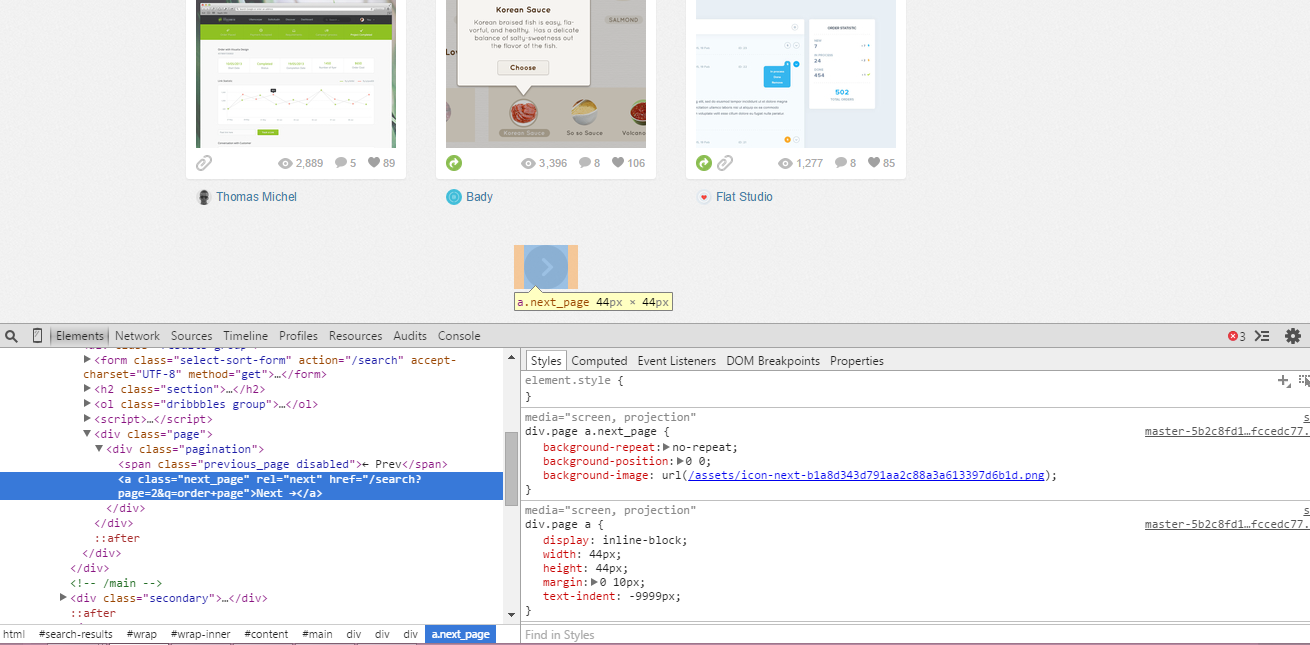
找到下一页的URL。
递归。不解释。
全部代码
import requests
import bs4
import urllib.request
import os
root_url = 'https://dribbble.com/'
search_url = 'search?q=order+page'
index_url = root_url+ search_url
def get_page_images(page_url):
img_url_list = get_page_urls(page_url)
#切片过滤多出来的链接
for _url in img_url_list[:23:2]:
img_url = get_img_url(_url)
print(img_url)
for url in img_url:
filename = url.split('/')[-1].split('.')[0]
file_ext = '.'+url.split('.')[-1]
foldername = search_url.split('=')[-1]
#如果有文件夹,就在文件夹里保存图片,
#如果没有该文件夹,那么创建foldername的新文件夹
if os.path.exists("D:/Python/pycon-scraper/img/"+foldername+"/") == 0:
os.mkdir("D:/Python/pycon-scraper/img/"+foldername+"/")
print(filename)
print(file_ext)
path = 'D:/Python/pycon-scraper/img/'+foldername+"/"+filename+file_ext
print(path)
#用这个函数从URL下载文件,保存到PATH中
data = urllib.request.urlretrieve(url,path)
next_page = has_next_page(page_url)
if next_page:
print("yes")
get_page_images(root_url+next_page[0])#递归,因为返回的是list,所以取第一个字符串元素
def get_page_urls(page_url):
response = requests.get(page_url)
soup = bs4.BeautifulSoup(response.text)
return [a.attrs.get('href') for a in soup.select('div.dribbble-img a')]
def get_img_url(half_url):
response = requests.get(root_url + half_url)
soup = bs4.BeautifulSoup(response.text)
attach_list = [a.attrs.get('href') for a in soup.select('ul.thumbs a')]
if(attach_list):
return get_attach_url(attach_list)
img_url = [a.attrs.get('src') for a in soup.select('div.single-grid img')]
return img_url
def has_next_page(page_url):
response = requests.get(page_url)
soup = bs4.BeautifulSoup(response.text)
return [a.attrs.get('href') for a in soup.select('div.pagination a.next_page')]
def get_attach_url(attach_list):
img_url=[]
for attach_url in attach_list:
response = requests.get(root_url + attach_url)
soup = bs4.BeautifulSoup(response.text)
img_url+=[a.attrs.get('src') for a in soup.select('div#viewer-img img')]
return img_url
get_page_images(index_url)###并行处理优化
现在的脚本可以成功运行了,如果我要爬几百张图可能得等上几个小时。我们要找到我们程序的瓶颈,然后想办法优化,不是吗?
我们程序的流程:加载HTML代码0.5s->获取URL0.0s->下载图片2~3s。
看出问题在哪了吗?
我们使用一个拥有8个可并行化进程的进程池(进程数为CPU核数的2倍),同时下载图片。
代码非常简洁:
from multiprocessing import Pool
def show_video_stats(options):
p = Pool(8)
p.map(get_page_images, [search_url1,search_url2,search_url3])处理异常
在下载过程中会出现一些为止异常。如果你不及时处理异常的话,那么异常就会一层层地抛出,直到程序中止为止,这些异常可能只是找不到图片,或者网络连接过慢。如果因为这些外部因素而造成我们程序的中止,以致再跑一遍的话,是非常不合算的。所以我们要加上异常的捕获(但是可以不处理,直接pass)
try:
#用这个函数从URL下载文件,保存到PATH中
data = urllib.request.urlretrieve(url,path)
except:
pass最终版
从dribbble上最后抓下来2G的资源,耗时半个小时。感觉还是挺满意的。
最终代码如下:
import requests
import bs4
import urllib.request
import os
from multiprocessing import Pool
root_url = 'https://dribbble.com/'
search_url1 = 'search?q=mobile'
search_url2 = 'search?q=material+design'
search_url3 = 'search?q=metro'
def get_page_images(search_url):
try:
img_url_list = get_page_urls(root_url+search_url)
#切片过滤多出来的链接
for _url in img_url_list[:23:2]:
img_url = get_img_url(_url)
print(img_url)
for url in img_url:
filename = url.split('/')[-1].split('.')[0]
file_ext = '.'+url.split('.')[-1]
foldername = search_url.split('=')[-1]
#如果有文件夹,就在文件夹里保存图片,
#如果没有该文件夹,那么创建foldername的新文件夹
if os.path.exists("D:/Python/pycon-scraper/img/"+foldername+"/") == 0:
os.mkdir("D:/Python/pycon-scraper/img/"+foldername+"/")
print(filename)
print(file_ext)
path = 'D:/Python/pycon-scraper/img/'+foldername+"/"+filename+file_ext
print(path)
try:
#用这个函数从URL下载文件,保存到PATH中
data = urllib.request.urlretrieve(url,path)
except:
pass
next_page = has_next_page(root_url+search_url)
if next_page:
print("yes")
get_page_images(next_page[0])#递归,因为返回的是list,所以取第一个字符串元素
except:
pass
def get_page_urls(page_url):
response = requests.get(page_url)
soup = bs4.BeautifulSoup(response.text)
return [a.attrs.get('href') for a in soup.select('div.dribbble-img a')]
def get_img_url(half_url):
response = requests.get(root_url + half_url)
soup = bs4.BeautifulSoup(response.text)
attach_list = [a.attrs.get('href') for a in soup.select('ul.thumbs a')]
if(attach_list):
return get_attach_url(attach_list)
img_url = [a.attrs.get('src') for a in soup.select('div.single-grid img')]
return img_url
def has_next_page(page_url):
response = requests.get(page_url)
soup = bs4.BeautifulSoup(response.text)
return [a.attrs.get('href') for a in soup.select('div.pagination a.next_page')]
def get_attach_url(attach_list):
img_url=[]
for attach_url in attach_list:
response = requests.get(root_url + attach_url)
soup = bs4.BeautifulSoup(response.text)
img_url+=[a.attrs.get('src') for a in soup.select('div#viewer-img img')]
return img_url
if __name__ == '__main__':
p = Pool(8)
p.map(get_page_images, [search_url1,search_url2,search_url3])Tags: python